
Lingo3G Workbench is an app you can use to quickly try, tune and experiment with Lingo3G clustering. Out of the box, Workbench will let you apply Lingo3G clustering to web search results, PubMed, Elasticsearch and Solr search results, Excel, OpenOffice, CSV spreadsheets and JSON and XML files.
Workbench can visualize the clusters using Carrot Search FoamTree and Circles visualizations. You can use Workbench to experiment with Lingo3G parameters and observe the impact on the results in real time.
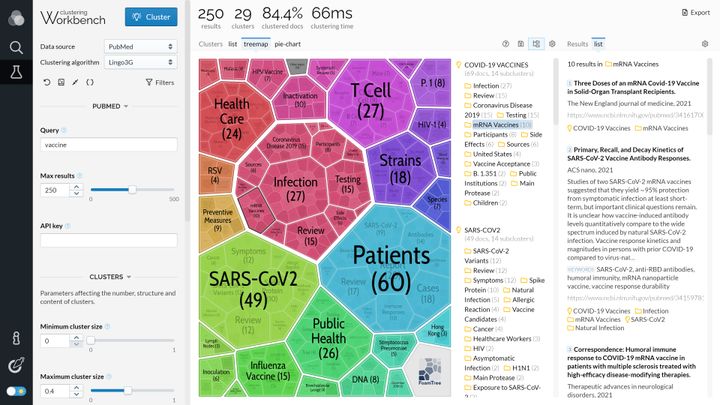
This screen shot shows search results for the query vaccine clustered into a 2-level hierarchy. The clusters are visualized using Carrot Search FoamTree.
Instant analysis of small-to-medium quantities of text
Lingo3G organizes collections of text documents into clearly-labeled hierarchical folders. In real-time, fully automatically, without external knowledge bases.

Instant overview
Get a concise summary of the subjects discussed in a set of documents.

More efficient browsing
Navigate straight to the documents you need using clearly-labeled folders.

Query refinement
Refine the initial query and "drill down" on a specific subject based on cluster labels.
 {REST}
{REST}


Painless integration into any environment using:
Java API, REST API, Solr or Elasticsearch plugins.
Accurate, blazing-fast, stateless

Useful hierarchical clusters
Lingo3G aims to produce clusters with concise, varied, relevant and human-readable labels.

Autonomous
No external taxonomies or knowledge bases needed, Lingo3G categorizes documents based only on their text.

High performance
On a desktop machine, Lingo3G clusters 100 search results in about 5 ms. Clustering 10.000 abstracts takes ~1 s.

Synonyms
You can add synonym definitions, such as photos = pictures = pics = photographs, to increase the quality of clustering

Label filtering
You can boost or suppress specific cluster labels to highlight product names or remove abusive language.

Tuning application
Tuning of clustering characteristics and performance in a dedicated GUI application called Lingo3G Workbench.

19 languages supported
Including English, German, French, Chinese Simplified, Thai and Arabic.

100% stateless
Lingo3G is a stateless system: data-in, clusters-out. This makes horizontal scaling a breeze.

REST/JSON API
Stateless REST/JSON API for integration with any programming language.

Pure Java library
Lingo3G works on any system supporting Java 11 or higher, no platform-specific dependencies.

Open source foundation
Lingo3G is based on the Carrot2 framework. If you've used Carrot2, switching to Lingo3G will be a breeze.
Dozens of happy customers around the globe

AcclaimIP is the fastest, most intuitive patent analytics and landscape solution available.
AcclaimIP uses Lingo3G to cluster patent documents. Not only are the clusters a great way to organize and visualize large sets of patents, but the theme extraction doubles as a keyword tool giving our customers yet another way to discover important search terms.
Matt Troyer, President at AcclaimIP, USA

eTools is the transparent Metasearch Engine built in Switzerland.
We chose Lingo3G because it exceeded our expectations in several ways: easy to integrate, many configuration options and extremely fast and lightweight. Besides that, we are always pleased with the professional care and responsiveness of the Carrot Search team.
Stephan Schmid, CEO at Comcepta, Switzerland

EPPI-Centre uses Lingo3G in its systematic reviewing software, EPPI-Reviewer.
A recent evaluation found overwhelming support for using Lingo3G, enabling users to make connections that they had not been able to predict in advance, “broadening understanding”, and so leading them to important new places.
Dr James Thomas, Associate Director, EPPI-Centre, Social Science Research Unit, Institute of Education, London
Questions & Answers
What are the applications of Lingo3G?
Lingo3G is stateless and processes all data in-memory. This makes it particularly suitable for clustering data coming from highly-dynamic collections, such as search results or social conversations.
Having said that, Lingo3G will be appropriate for processing any collection of texts where the total size does not exceed a few tens of megabytes.
What is the largest collection Lingo3G can handle?
Lingo3G was designed to perform real-time in-memory clustering of small and medium collections of documents, which roughly corresponds to about 5,000 documents, a few kilobytes each.
The upper limit very much depends on the characteristics of your documents. Some of our customers report that they successfully use Lingo3G with as many as 100,000 documents. Please contact us for an evaluation license and performance tuning advice.
For collections spanning millions of documents and gigabytes of text, consider Lingo4G.
Does Lingo3G come with end-user applications?
Yes. Lingo3G comes with two browser-based apps for end users: Search Results Clustering and Clustering Workbench. We created the apps to help you quickly try Lingo3G clustering on your data. However, if you find the apps useful in your daily text mining work, feel free to use them on a regular basis.
While we plan to add new features to the end-user apps, our priority is the development of the Lingo3G clustering algorithm core.
How is Lingo3G licensed?
We require one Lingo3G license per one physical or virtual server that runs Lingo3G binaries, regardless of the number of cores on the server, the number of users or requests handled by the server.
For large-scale or non-typical deployment scenarios, such as OEM distribution, please get in touch.
What is the cost of a Lingo3G license?
The cost of a license depends on the edition, please contact us for a quote.
Is there a free version?
Yes, you can use the algorithms available in the Carrot2 open source framework. Please see the comparison for more details.
Can I get a trial license?
Absolutely! Please get in touch for a free evaluation package.
Where can I learn more about Lingo3G?
The best place to start would be the Lingo3G Manual. For an in-depth introduction to search results clustering algorithms and engines, please see:
A survey of Web clustering engines. ACM Computing Surveys (CSUR), Volume 41, Issue 3 (July 2009), Article No. 17, ISSN: 0360-0300 (PDF).
The paper reports on the evaluation of a number of search results clustering engines, including Lingo3G.