
Clustering engine for millions of documents and gigabytes of text
Free trial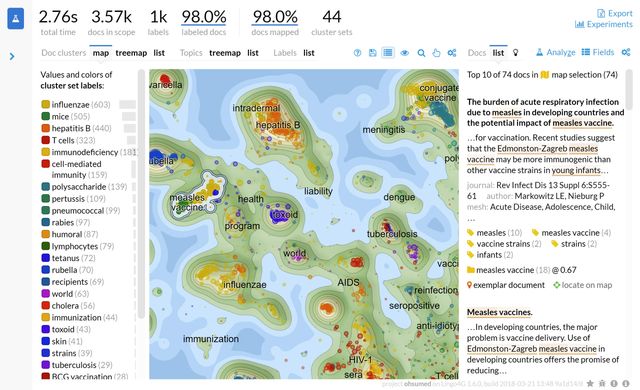
Lingo4G is a software component you can use to implement interactive exploration of millions of documents spanning gigabytes of text.
Lingo4G Explorer, pictured in the screen shot, shows what you can build with Lingo4G REST API. Lingo4G Explorer is also a great tool for quick experiments with Lingo4G-powered large-scale text clustering.
The screen shot shows a 2D map visualization of 3.5k medical paper abstracts related to vaccines. Textually-similar abstracts are clustered together on the map. The panel on the right shows the top abstracts lying in the map region described as measles vaccine. Phases specific to the selected map region are highlighted in the text of the abstract.
Note: analysis presented in the screen shot took 2.76s to compute on a modern 16-core workstation with SSD storage. Analysis times will vary depending on the parameters of your hardware.
Meaningful insights from large quantities of text
Lingo4G enables interactive exploration of millions of documents and gigabytes of text. In near-real-time, fully automatically, without external knowledge bases.

Overview and drill-down
Get an overview of thousands of documents within seconds, instantly drill-down to documents of interest.

Flexible API
Build custom text mining pipelines ranging from simple search to 2D mapping, time-series analysis and duplicate detection.

Engaging visualizations
Combine topics, clusters and 2D document maps into powerful visualizations.
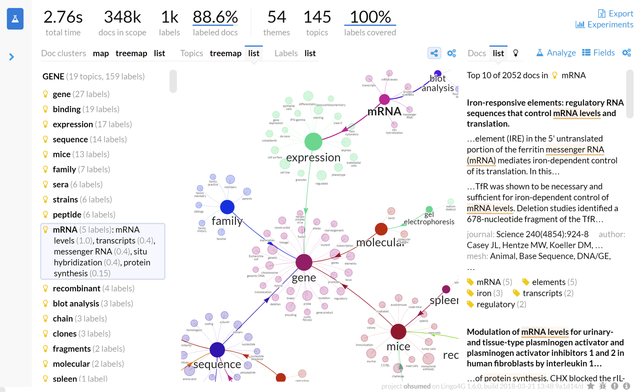
Lingo4G can extract the topics discussed in hundreds of thousands of documents within seconds.
The screen shot shows subtopics of the gene topic identified in nearly 350k abstracts of medical articles. The graph presents lexical relationships between subtopics, while the content view on the right side shows topical phrases in context by highlighting them in the text of the analyzed documents.
Note: analysis presented in the screen shot took 2.76s to compute on a modern 16-core workstation with SSD storage. Analysis times will vary depending on the parameters of your hardware.
Near-real-time topic discovery
Lingo4G can extract the topics discussed in hundreds of thousands of documents, along with lexical relationships between them, within seconds.
Topical phrases in context
Lingo4G can highlight selected topical phrases in the document text to put them in context and bring up the relevant parts.
Large-scale processing
Lingo4G can arrange hundreds of thousands of documents into non-overlapping clusters and 2D maps to help plan, execute and refine research.
Data slicing and filtering
Choose the document subset to analyze by typing a query, picking an area from the document map or selecting a topic or cluster to drill down on.
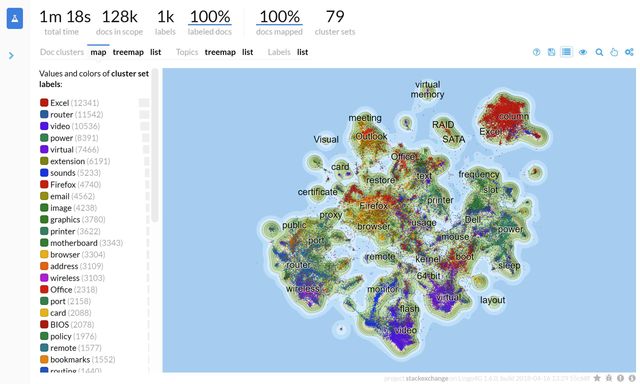
On modern hardware, Lingo4G can generate document clustering and map visualizations for hundreds of thousands of documents within minutes.
The screen shot shows the map of 128k SuperUser.com questions. Each dot represents one document, colors correspond to top-level document clusters.
Different thematic areas are clearly visible: Excel-related questions in the top-right corner, network issues in the bottom-left corner, posts about web browsers in the middle. Smaller outlier groups, such as questions about disk drives (RAID, SATA) are also highlighted.
Note: analysis presented in the screen shot took about 1 minute to compute on a modern 16-core workstation with SSD storage. Analysis times will vary depending on the parameters of your hardware.
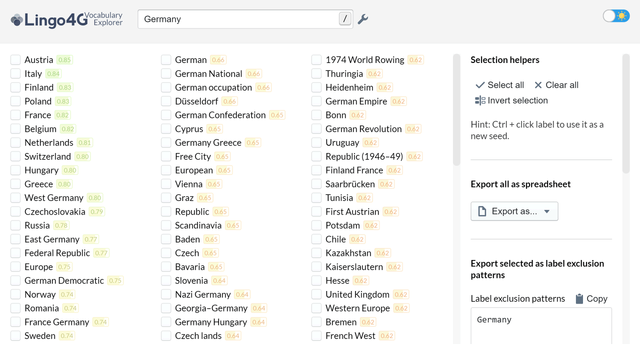
Lingo4G can build multidimensional vector representations of words, phrases and documents. Similar to word2vec, these representation can be used to find semantic relationships between labels and documents.
The screenshot shows a list of words and phrases similar to Germany, based on English Wikipedia data. Notice that the top of the list is occupied by European countries near Germany. The relationships were derived based only on the text of the input documents, no external taxonomies or resources were used.
Semantic relationships between words, phrases and documents
Lingo4G can build vector representations of words, phrases and documents. They allow finding semantically-similar documents, even if the documents don't share common words or phrases.
All text processing tasks available in Lingo4G, such as document search, clustering or 2D mapping, can use vector-based semantic similarity.
Flexible API
Lingo4G exposes all its text processing capabilities through a flexible REST/JSON API. The API allows assembling simple text processing components into pipelines of varying complexity. The tasks you can perform include:
- document search and retrieval,
- document clustering and 2D mapping,
- extracting topics from documents,
- finding near-duplicate documents.
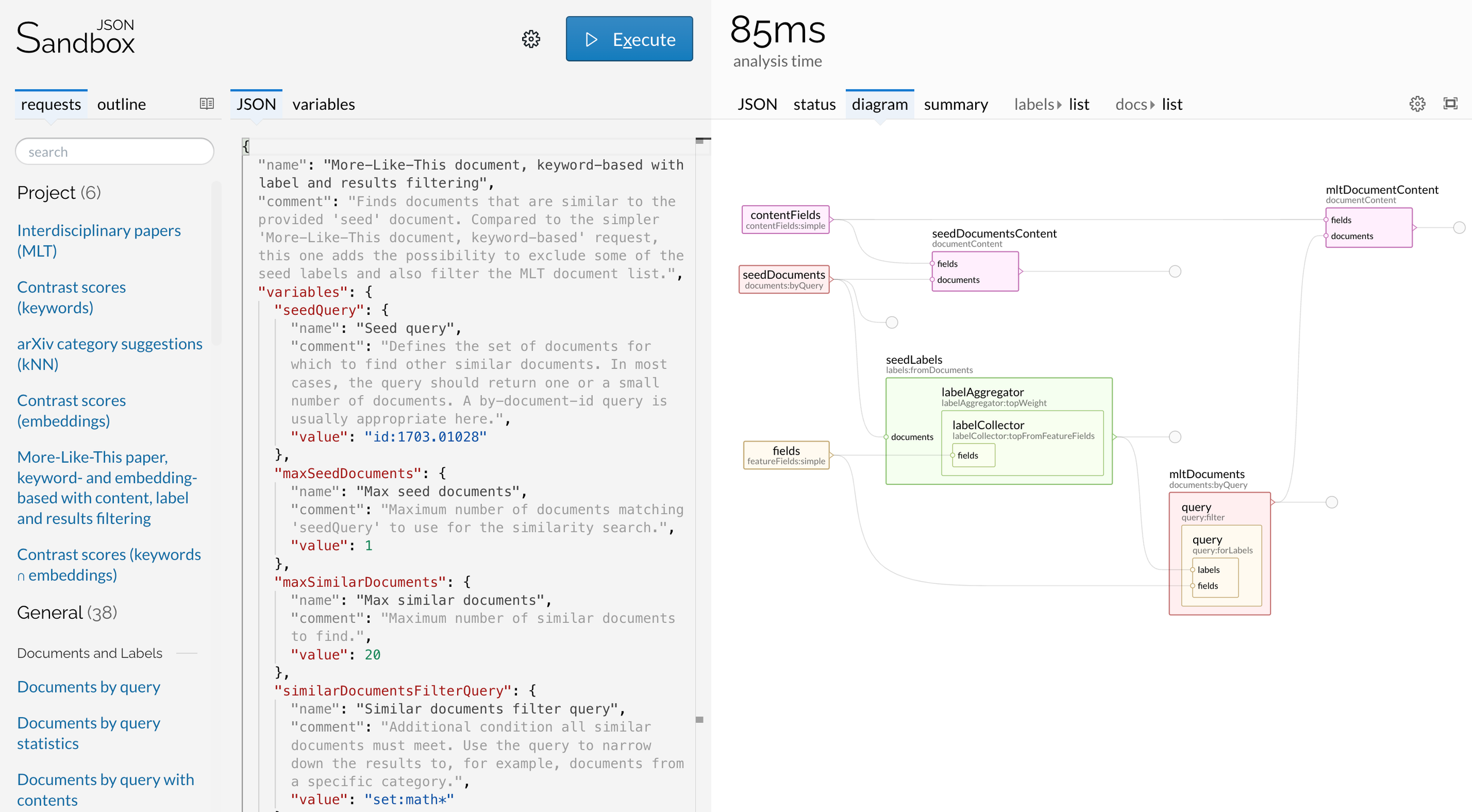
Lingo4G exposes all its text processing capabilities through a flexible REST/JSON API. The screenshot shows the JSON Sandbox app, which you can use to edit, execute and tune Lingo4G analysis requests.
The request shown in the screenshot finds documents that are similar to the user-provided seed document. The panel on the right shows the data flow between the low-level text processing components defined by the request.
Fast, automatic, easy to integrate

Fast indexing
Lingo4G can index 200–2000 MB of text per minute. Adding, updating or deleting docs does not require reindexing.

Near-real-time processing
Once Lingo4G indexes your collection, it can extract topics, cluster or 2D-map document within seconds.

No external taxonomies
Lingo4G processes documents based only on their textual content, no external dictionaries or taxonomies required.

Semantic processing
Lingo4G can learn vector representations of documents and phrases to identify semantic relationships in data.

Clustering
Lingo4G can organize documents into labeled groups, based on keyword or semantic vector similarity.

2D mapping
Lingo4G can lay out documents on a labeled 2D map, keeping similar documents close, based on keyword or vector similarity.

Duplicate detection
Lingo4G can identify pairs of documents with highly-overlapping content, which you can use to detect duplicates or plagiarism.

Stop word discovery
Lingo4G can automatically identify the meaningless phrases specific to your data, such as present invention for patent data.

Full-text search
Should you need the good old full-text search over your collection, Lingo4G can do that too.

Tuning
The Lingo4G Explorer application will let you get started quickly and tune every aspect of topic extraction and clustering.
Easy integration
Lingo4G exposes a JSON-based REST API you can call from any programming language to get analysis results.

Custom analysis pipelines
Use REST API to build more complex pipelines, such as nearest-neighbor classification or time series analysis.
Questions & Answers
What are the applications of Lingo4G?
The natural use case is exploration of large volumes of human-readable text, such as scientific papers, business or legal documents.
You can combine Lingo4G basic text processing operations to build, for example, the following functionalities:
-
Recommending tags for a new document based on the tags of the documents existing in the index.
-
Example-based document search: finding documents similar to the example seed document the user provides, based on keyword or semantic vector similarity.
-
2D map visualization of documents where semantically-similar documents occupy the same area of the map. Colors of the document marker on the map indicate the cluster to which the document belongs. Salient phrases extracted from documents describe the densely-populated areas of the map.
-
Finding documents with highly overlapping content, which may suggest the documents are duplicates or plagiarised copies. Lingo4G can perform such a process efficiently for millions of documents at once.
What is the largest collection Lingo4G can handle?
On modern hardware with a high-core-count CPU and fast SSD storage, Lingo4G can handle collections reaching hundreds of gigabytes or a terabyte of text.
If you'd like to test Lingo4G on such a large data set, Lingo4G comes with built-in support for indexing patent grant and application documents available from US Patent and Trademark Office. The collection is currently about 500 GB of text.
One important factor to consider is that currently Lingo4G does not offer distributed processing. This means that the maximum reasonable size of the project will be limited by the amount of RAM, disk space and processing power available on a single virtual or physical server.
Which languages does Lingo4G support?
Currently, Lingo4G can only process English text. If you'd like to apply Lingo4G to content written in a different language, please contact us.
What are the system requirements for Lingo4G?
Lingo4G can run on any platform supporting Java 17 or later. While processing cannot currently be distributed to multiple machines, a high-end workstation with fast SSD storage should be capable of handling collections of several tens of gigabytes. For most data sets not exceeding gigabytes, any computer with 4GB of memory and some disk space will be sufficient. We very much recommend using SSD drives to store Lingo4G indices. Please see the Requirements section of Lingo4G manual for more details.
How is Lingo4G licensed?
We require one Lingo4G license per one physical or virtual server that runs Lingo4G binaries, regardless of the number of cores on the server, the number of users and number of collections handled by the server.
For large-scale or non-typical deployment scenarios, such as OEM distribution, please get in touch.
How many collections can I process on one server?
There are no restrictions on the number of Lingo4G instances running on one physical or virtual server. The only limit may be the capacity of the server, including RAM size, disk space and the number of CPUs.
What is the cost of a Lingo4G license?
The cost of a license depends on the edition, please contact us for a quote.
Can I get a trial license?
Absolutely! Please get in touch for a free evaluation package.
I have a Lingo3G license, will I receive Lingo4G as an upgrade?
No. Lingo3G and Lingo4G are two separate products we intend to offer and maintain independently. Lingo3G will remain an engine for real-time clustering of small and medium collections, while Lingo4G will address clustering of large data sets. Therefore, Lingo4G is not an upgrade to Lingo3G, but a complementary offering.
Having said that, if you would like to switch from Lingo3G to Lingo4G, we offer a license trade-in option and count the initial Lingo3G license purchase fee towards the Lingo4G license fee.
Can I use the dotAtlas map visualization component in my application?
The dotAtlas map visualization component shipping with Lingo4G Explorer is currently pre-release software. It's been battle-tested for months by early adopters, but lacks finalized API and documentation.
If you'd like to try integrating dotAtlas into your software, please let us know. We'll be happy to share the pre-release version along with code examples and initial guidance.
We will not charge any extra fees for the pre-release versions of dotAtlas. Once it enters the official product suite, the use of dotAtlas will require a license fee similar to the one that applies for Carrot Search FoamTree.