
How does it work?
First, let Lingo4G index all documents you'd like to process. Then, you can make requests to analyze subsets of the index to get topics and clusters.
(Which is much like an enterprise search engine needs to index documents before you can search them.)You can get started with Lingo4G in four simple steps.
-
Prepare your data
Convert your documents to a key-value JSON format, write a project descriptor JSON file to define fields in your documents.
Lingo4G can also extract and index contents of PDF, Word, HTML and plain text files.
Alternatively, start with some built-in data sets: Stack Exchange Q&A data, PubMed Open Access articles, clinicaltrials.gov reports, IMDb movie descriptors, research.gov grant descriptions, Wikipedia or US patents.
[ { "id": "97", "title": "What Windows services can I safely disable?", "question": "I'm trying to improve the boot time and general performance of a Windows XP machine. Are there any services that I can safely disable?", "tag": [ "windows", "services" ], "comments": 8, "views": 4808, "acceptedAnswer": "Black Viper maintains what is considered by many the definitive guide to Windows services. http://www.blackviper.com/category/guides/service-configurations/\n" }, { "id": "366", "title": "How do you map a Mac keyboard to PC layout?", "question": "ay I have a Mac keyboard and want to use it on a PC. Some of the keys aren't quite right. How do I map them correctly?", ... }, { ... } ... ] -
Index the data
Let Lingo4G preprocess the data first, much like a search engine needs to index documents before they are searchable:
$ l4g index -p your-project.jsonOn modern hardware indexing speed is in the order 200–2000 MB of text per minute.
This video shows the process of indexing SuperUser.com questions in Lingo4G large-scale text clustering engine.
-
Analyze
Start the Lingo4G REST API server Lingo4G REST API server:
$ l4g server -p your-project.jsonUse the Lingo4G Explorer app to experiment with topic extraction, clustering and 2D mapping.
This video shows Lingo4G topic extraction and document clustering applied to the SuperUser.com questions and answers database. The user interface featured in this video is Lingo4G Explorer, a browser-based application that ships with Lingo4G.
-
Use the API
Launch the JSON Sandbox app to try Lingo4G Analysis API. Try the basic text processing building blocks, such as:
- query-based document search,
- salient phrase extraction,
- clustering phrases into topics,
- clustering and 2D-mapping of documents,
- duplicate document detection.
Review examples of more complex requests, such as k-nearest-neighbors classification or example-based document search.
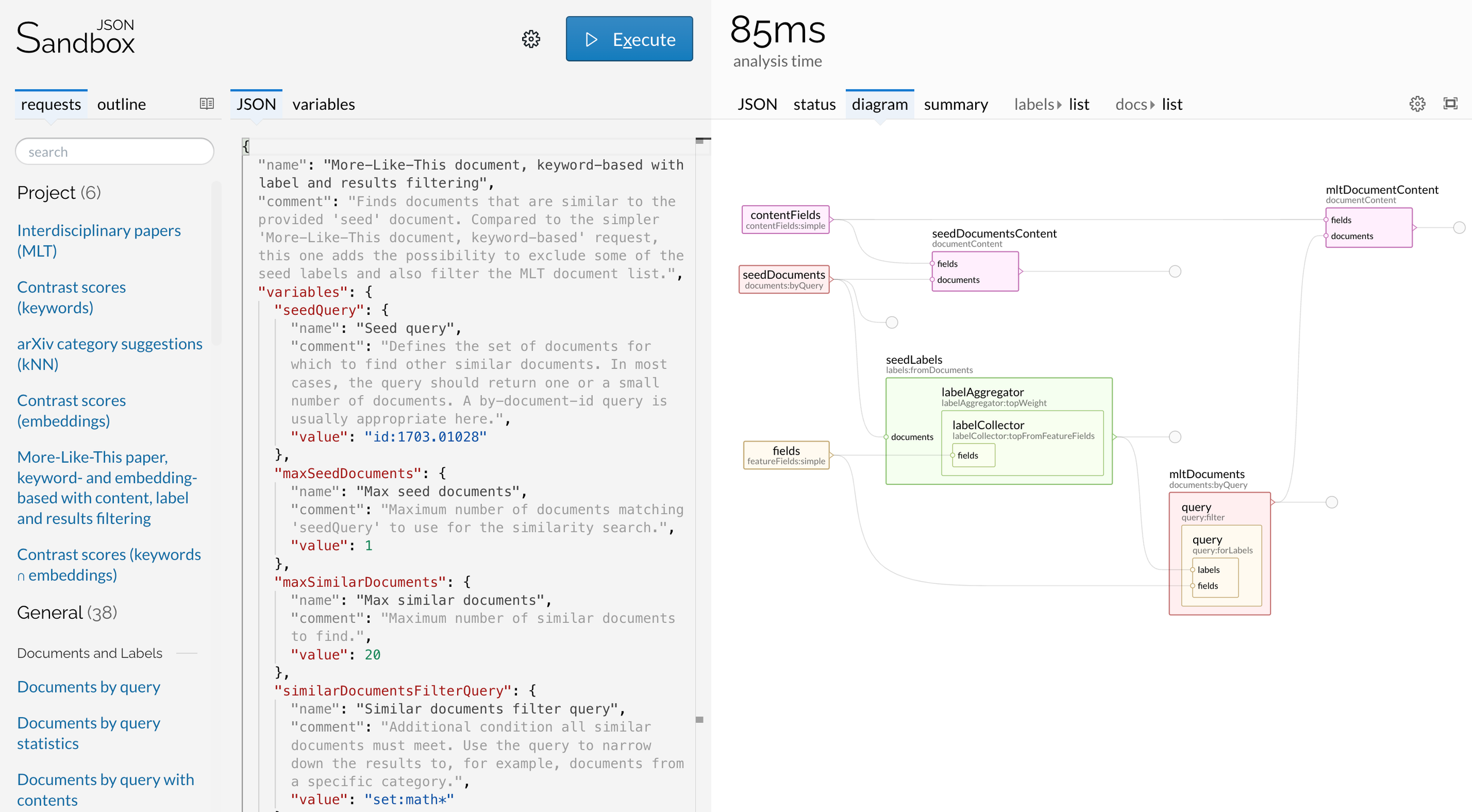
The screenshot shows the JSON Sandbox app, which you can use to edit, execute and tune Lingo4G analysis requests.
The request shown in the screenshot finds documents that are similar to the user-provided seed document. The panel on the right shows the data flow between the low-level text processing components defined by the request.
Questions & Answers
Is Lingo4G an end-user product?
No. Lingo4G was designed as a software component rather than a complete end-user application. The primary use case for Lingo4G is integration into larger software suites. Therefore, some programming experience will be required to get started and to use Lingo4G.
Having said that, Lingo4G comes with a GUI application, called Lingo4G Explorer, meant to allow rapid experiments and tuning of topic extraction and clustering. If Lingo4G Explorer meets the needs of your end users, feel free to use it. One thing to bear in mind is that our primary focus is on the underlying topic extraction and clustering algorithms, developing and extending Lingo4G Explorer is a lower priority.
What does near real-time processing mean?
Near real-time processing means that in most cases Lingo4G will be able to extract topics for a subset of documents in your index within seconds, regardless of the size of the subset. Clustering of tens or hundreds of thousands of documents may take several minutes.
To achieve near real-time performance during analysis, Lingo4G needs to index your collection first. Indexing is a one-time process where the initial text processing (tokenization, label extraction) is applied. On modern hardware, indexing speed is in the order of 200–500 MB per minute.
The performance of both indexing and analysis is crucially dependent on the technology used to store Lingo4G index. To maximize performance and CPU utilization, use fast SSD drives.
Can I add, update or remove documents from an existing Lingo4G index?
Yes. With Lingo4G version 1.7.0 or later you can add, update and delete without re-indexing the whole collection.
Does Lingo4G come as an Elasticsearch or Solr plugin?
No. Lingo4G is standalone software that manges its own index. The index contains Lingo4G-specific data that is not typically present in indices created by enterprise search engines. Therefore, Lingo4G will have to run in parallel to an Elasticsearch or Solr instance you might already have. As a result, the same will be stored separately in the two systems.
Technical details
If you'd like to delve into technical details, Lingo4G manual has them all.
-
- Architecture — building blocks of Lingo4G, the two-phase processing workflow.
- Indexing — document sources, feature and stop label extraction.
- Embeddings — vector representations that capture semantic relationships between words, phrases and documents.
- Analysis — analysis scopes, labels, topics, clustering and retrieval of documents.
- Quick start — detailed steps to get your first Lingo4G project based on sample data up and running.
- Requirements — why it is crucial to run Lingo4G on SSD drives.
- Installation — contents of Lingo4G distribution, installation procedure.
- Indexing JSON data — creating descriptor for your Lingo4G project, invoking indexing and analysis.
- REST API — calling conventions, endpoints, parameters, responses.
- Analysis API overview — building Lingo4G analysis pipeline specifications.
- Analysis API reference — complete reference of indexing and analysis parameters you can customize.